실시간 로그 분석 서비스 구축 가이드¶
Warning
곧 배포 예정입니다.
Amazon Athena , Google BigQuery 등의 데이터 쿼리 서비스를 이용하면 손쉽게 실시간 로그분석 서비스를 구축할 수 있다.
Note
데이터 쿼리 서비스의 과금체계는 스캔한 데이터 용량에 기반한다. 따라서 이에 맞는 적절한 파티셔닝 전략이 필요하며 보다 자세한 내용은 해당 서비스 문서를 참고한다.
Amazon Athena¶
Amazon Athena 를 이용해 M2 서비스 로그 분석서비스를 구축하는 방법을 다룬다.
Note
S3는 이미 생성되어 있다고 가정한다.
로그 S3 백업 저장소 구성¶
access.log , origin.log 를 실시간으로 S3에 백업하는 것으로 시작한다.
See also
먼저 다음과 같이 로그 저장소를 구성한다.
{
"env": {
"log": {
"repository": {
"list": [
{
"name": "log_storage",
"path": "/mypath/year={timestamp.year}/month={timestamp.month}/day={timestamp.day}/hour={timestamp.hour}/min={timestamp.minute}/type={logtype}/domain={domain}/{hostname}_{ip}_{timestamp}.log"
"rolling": "*/5 *",
"compression": {
"enable": true
},
"endpoint": ...
}
]
}
}
}
}
위 구성에서 눈여겨 봐야하는 설정은 다음과 같다.
path로그 업로드 경로를 지정한다. 데이터를 디렉토리로 구조화(=파티셔닝)해야 질의범위에 따라 부과되는 비용을 최소화할 수 있다.# 시간대를 우선 특정하는 전략 /year={timestamp.year}/month={timestamp.month}/day={timestamp.day}/hour={timestamp.hour}/min={timestamp.minute}/type={logtype}/domain={domain}/{hostname}_{ip}_{timestamp}.log # 서비스를 우선 특정하는 전략 /domain={domain}/year={timestamp.year}/month={timestamp.month}/day={timestamp.day}/hour={timestamp.hour}/min={timestamp.minute}/type={logtype}/{hostname}_{ip}_{timestamp}.log # 서버당 서비스를 우선 특정하는 전략 /hostname={hostname}/domain={domain}/year={timestamp.year}/month={timestamp.month}/day={timestamp.day}/hour={timestamp.hour}/min={timestamp.minute}/type={logtype}/{hostname}_{ip}_{timestamp}.log
rolling최소 단위로 5분을 권장한다. 너무 크게 나누면 한번에 스캔할 양이 많아진다. 너무 작게 나누면 관리가 어렵다.compression텍스트 데이터이기 때문에 압축을 통해 90% 이상 비용을 절감할 수 있다.
Warning
파티셔닝 예정이라면
path를 반드시 소문자로 지정한다.
로그백업 활성화¶
서비스되는 모든 가상호스트의 로그를 백업하려면 다음과 같이 기본 설정으로 저장소를 연결한다.
{
"functions": {
"operations": {
"log": {
"access" : {
"backup": [ "log_storage" ]
},
"origin" : {
"backup": [ "log_storage" ]
},
}
}
},
"hosting": [ ... ]
}
로그양이 지나치게 많을 수 있으므로, 특정 가상호스트의 로그만 백업이 가능하다.
다음은 foo.com 의 access.log 와 origin.log 를, bar.com 의 origin.log 만을 백업하는 예이다.
{
"hosting": [
{
"name": "foo.com",
... (생략) ...
"functions": {
"operations": {
"log": {
"access" : {
"backup": [ "log_storage" ]
},
"origin" : {
"backup": [ "log_storage" ]
},
}
}
}
},
{
"name": "bar.com",
... (생략) ...
"functions": {
"operations": {
"log": {
"origin" : {
"backup": [ "log_storage" ]
},
}
}
}
}
]
}
구성이 완료되었다면 이제 로그가 S3에 path 규칙에 맞추어 백업되는지 확인한다.
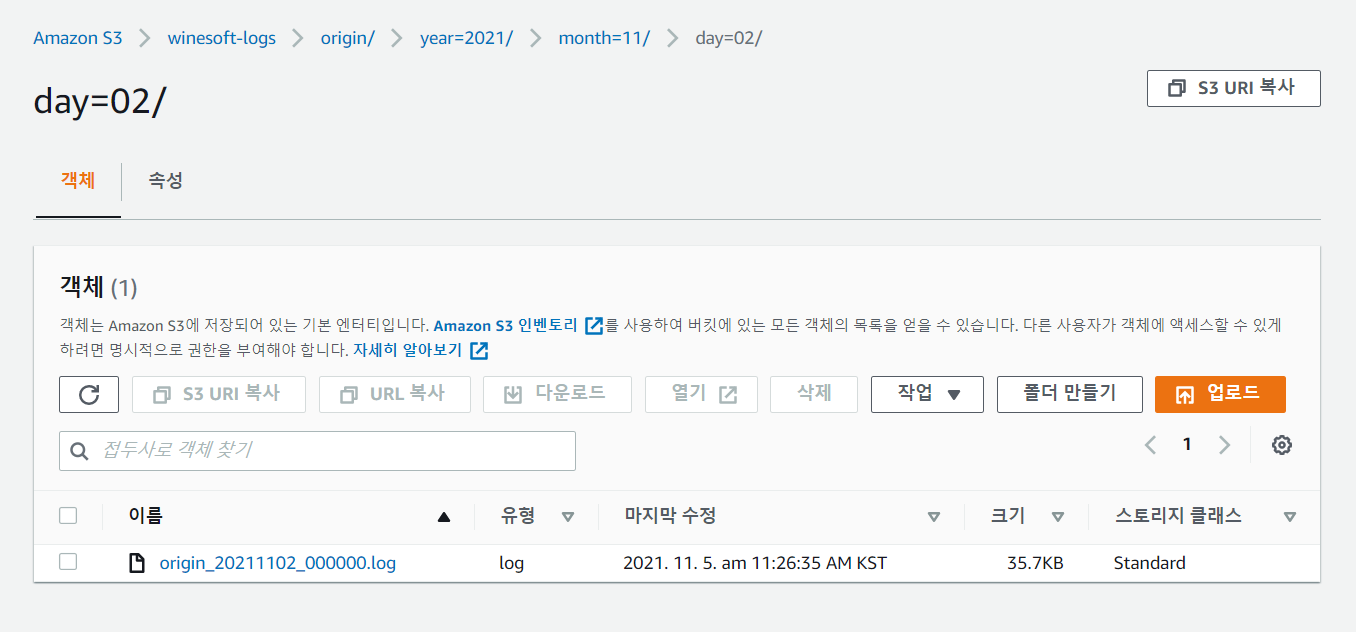
Athena 데이터베이스 생성¶
Athena 질의를 위해 로그 필드에 맞추어 데이터베이스를 생성한다.
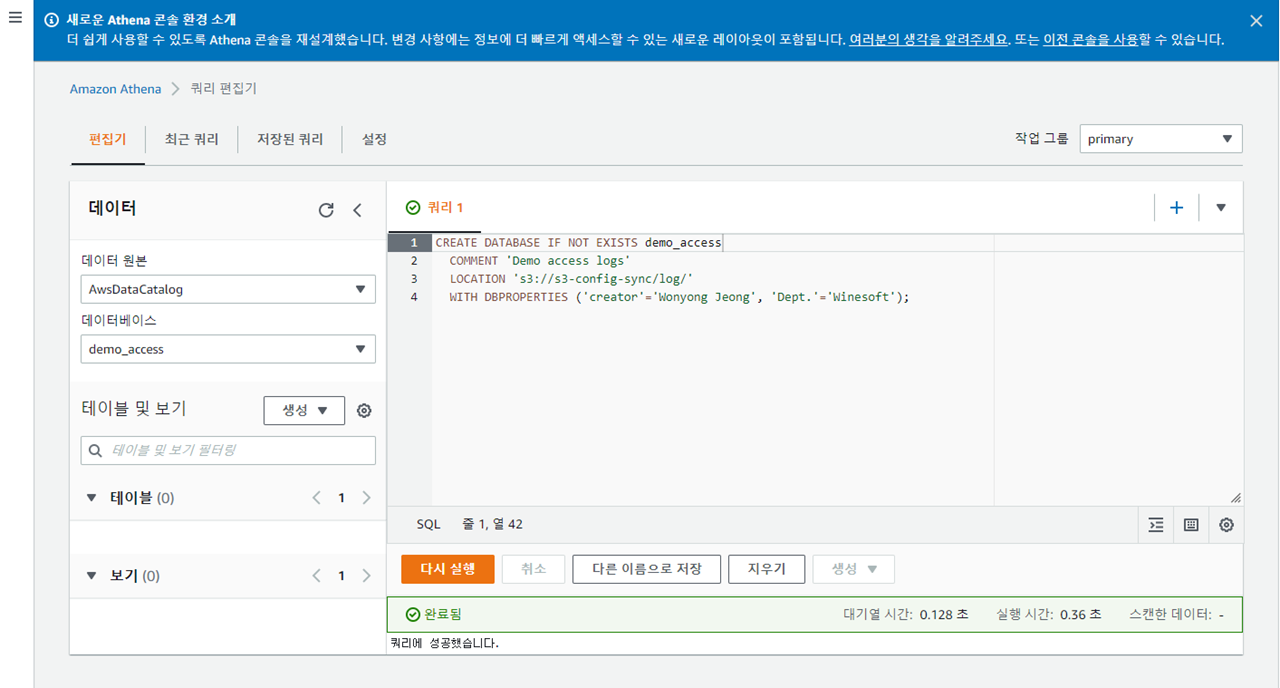
access.log 에 해당하는 access_logs 테이블 생성쿼리는 다음과 같다.
CREATE EXTERNAL TABLE IF NOT EXISTS access_logs (
`date` STRING,
`time` STRING,
`s-ip` STRING,
`cs-method` STRING,
`cs-uri-stem` STRING,
`cs-uri-query` STRING,
`s-port` STRING,
`cs-username` STRING,
`c-ip` STRING,
`cs-useragent` STRING,
`sc-status` STRING,
`sc-bytes` STRING,
`time-taken` STRING,
`cs-referer` STRING,
`sc-resinfo` STRING,
`cs-range` STRING,
`sc-cachehit` STRING,
`cs-acceptencoding` STRING,
`session-id` STRING,
`sc-content-length` STRING,
`time-response` STRING,
`x-transaction-status` STRING,
`x-fallback ` STRING ,
`x-ctx-id ` STRING
) PARTITIONED BY (`year` string, `month` string, `day` string, `hour` string, `min` string, `type` string, `domain` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)"
) LOCATION "s3://winesoft-logs/access"
TBLPROPERTIES ("has_encrypted_data"="false");
Note
쿼리 중
LOCATION은 S3경로를 입력한다.쿼리 중
PARTITIONED BY구문은 파티셔닝 전략인 로그백업path를 통해 사전 정의되었다.
origin.log 에 해당하는 origin_logs 테이블 생성쿼리는 다음과 같다.
CREATE EXTERNAL TABLE IF NOT EXISTS origin_logs (
`date` STRING,
`time` STRING,
`cs-sid` STRING,
`cs-tcount` STRING,
`c-ip` STRING,
`cs-method` STRING,
`s-domain` STRING,
`cs-uri` STRING,
`s-ip` STRING,
`sc-status` STRING,
`cs-range` STRING,
`sc-sock-error` STRING,
`sc-http-error` STRING,
`sc-content-length` STRING,
`cs-requestsize` STRING,
`sc-responsesize` STRING,
`sc-bytes` STRING,
`time-taken` STRING,
`time-dns` STRING,
`time-connect` STRING,
`time-firstbyte` STRING,
`time-complete` STRING,
`cs-reqinfo` STRING,
`cs-acceptencoding` STRING,
`sc-cachecontrol` STRING,
`s-port` STRING,
`sc-contentencoding` STRING,
`session-id` STRING,
`session-type` STRING,
`x-sc-chain-error` STRING,
`time-sock-creation` STRING,
`x-cs-retry` STRING,
`x-cs-extra-field` STRING,
`time-request` STRING,
`x-response-info` STRING,
`x-ctx-id` STRING
) PARTITIONED BY (
`year` string, `month` string, `day` string, `hour` string, `min` string, `type` string, `domain` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)"
)
LOCATION "s3://winesoft-logs/origin"
TBLPROPERTIES ("has_encrypted_data"="false");
질의와 갱신¶
이제 Athena 질의를 통해 실시간으로 로그 분석이 가능하다.
Note
WHERE 절 질의시 주의사항
컬럼명은 큰 따옴표를 사용한다.
값은 작은 따옴표를 사용한다.
올바른 예
SELECT * FROM access_logs WHERE “cs-method”='POST'
잘못된 예
SELECT * FROM access_logs WHERE “cs-method”=”POST”
SELECT * FROM access_logs WHERE ‘cs-method’=”POST”
다음은 클라이언트에게 응답된 500 응답코드만에 대한 질의이다.
SELECT * FROM access_logs WHERE "sc-status" = '500';
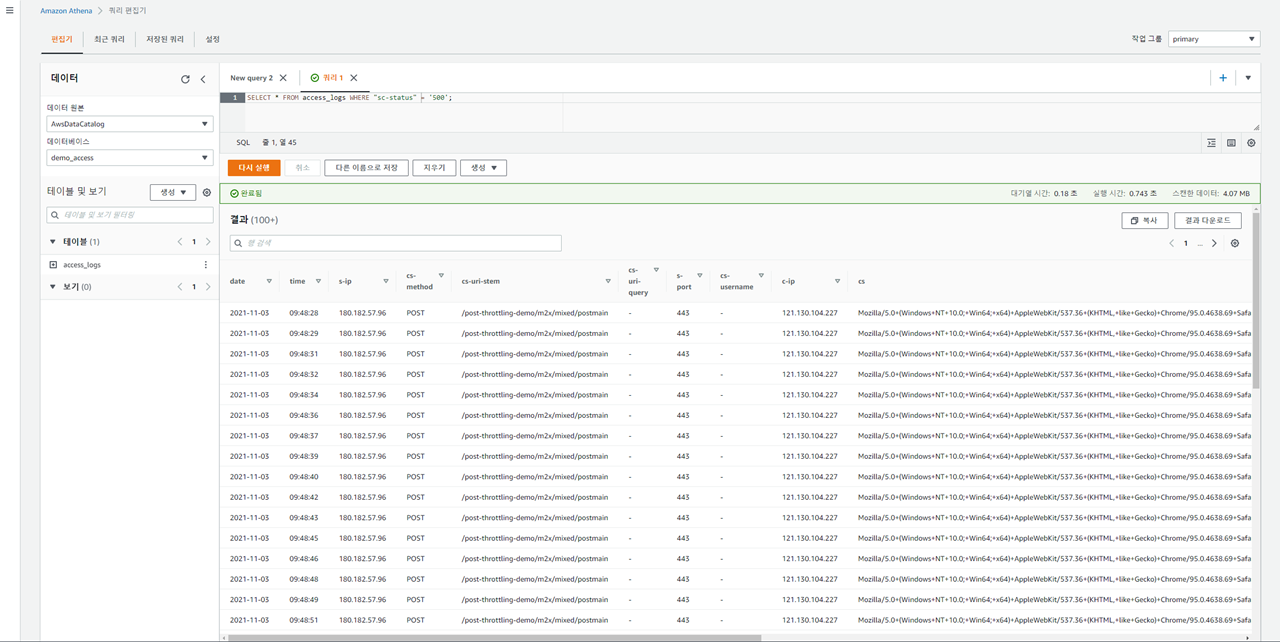
로그 필드의 기본 유형은 STRING 이기 때문에 범위질의 등 숫자타입의 표현이 필요한 경우 CAST 함수를 사용한다.
SELECT * FROM m2live_origin WHERE CAST("sc-content-length" AS INT) < 102580650;
SELECT * FROM m2live_origin WHERE CAST("sc-content-length" AS INT) BETWEEN 102400 and 204800;
이는 로그에서 해당 값의 부재시 기본 값을 - 문자로 표현하기 때문이다.
Important
로그가 5분 단위로 백업이 된다고 하여 항상 쿼리 결과에 반영되는 것은 아니다. 최신 데이터가 반영되려면 쿼리 수행 전 데이터베이스에 다음 쿼리를 수행한다.
MSCK REPAIR TABLE access_logs;
또는 5분마다 위 질의를 자동화하는 시스템을 구축한다. 보다 자세한 내용은 MSCK REPAIR TABLE 를 참고한다.
Google Cloud BigQuery¶
Google BigQuery 를 이용해 M2 서비스 로그 분석서비스를 구축하는 방법을 다룬다.
Note
S3는 이미 생성되어 있다고 가정한다.
로그 Storage 백업 저장소 구성¶
access.log , origin.log 를 실시간으로 Google Cloud Storage 에 백업하는 것으로 시작한다.
See also
먼저 다음과 같이 로그 저장소를 구성한다.
{
"env": {
"log": {
"repository": {
"list": [
{
"name": "google_storage",
"type": "google-cloud-storage",
"path": "/mypath/year={timestamp.year}/month={timestamp.month}/day={timestamp.day}/hour={timestamp.hour}/min={timestamp.minute}/type={logtype}/domain={domain}/{hostname}_{ip}_{timestamp}.log"
"rolling": "*/5 *",
"compression": {
"enable": true
},
"endpoint": {
"credential": '/usr/local/m2/stg-api-a000000000.json'
}
}
]
}
}
}
}
위 구성에서 눈여겨 봐야하는 설정은 다음과 같다.
rolling최소 단위로 5분을 권장한다. 너무 크게 나누면 한번에 스캔할 양이 많아진다. 너무 작게 나누면 관리가 어렵다.compression텍스트 데이터이기 때문에 압축을 통해 90% 이상 비용을 절감할 수 있다.
Note
로그 S3 백업 저장소 구성 에서 Partition 전략과 밀접히 다루어졌던 path 전략은 Google Cloud에서는 유효하지 않다.
따라서 로그관리 목적에 맞추어 구성하여도 무방하다.
로그백업 활성화¶
서비스되는 모든 가상호스트의 로그를 백업하려면 다음과 같이 기본 설정으로 저장소를 연결한다.
{
"functions": {
"operations": {
"log": {
"access" : {
"backup": [ "google_storage" ]
},
"origin" : {
"backup": [ "google_storage" ]
},
}
}
},
"hosting": [ ... ]
}
로그양이 지나치게 많을 수 있으므로, 특정 가상호스트의 로그만 백업이 가능하다.
다음은 foo.com 의 access.log 와 origin.log 를, bar.com 의 origin.log 만을 백업하는 예이다.
{
"hosting": [
{
"name": "foo.com",
... (생략) ...
"functions": {
"operations": {
"log": {
"access" : {
"backup": [ "google_storage" ]
},
"origin" : {
"backup": [ "google_storage" ]
},
}
}
}
},
{
"name": "bar.com",
... (생략) ...
"functions": {
"operations": {
"log": {
"origin" : {
"backup": [ "google_storage" ]
},
}
}
}
}
]
}
구성이 완료되었다면 이제 로그가 Google Storage에 path 규칙에 맞추어 백업되는지 확인한다.
BigQuery 데이터 세트 만들기¶
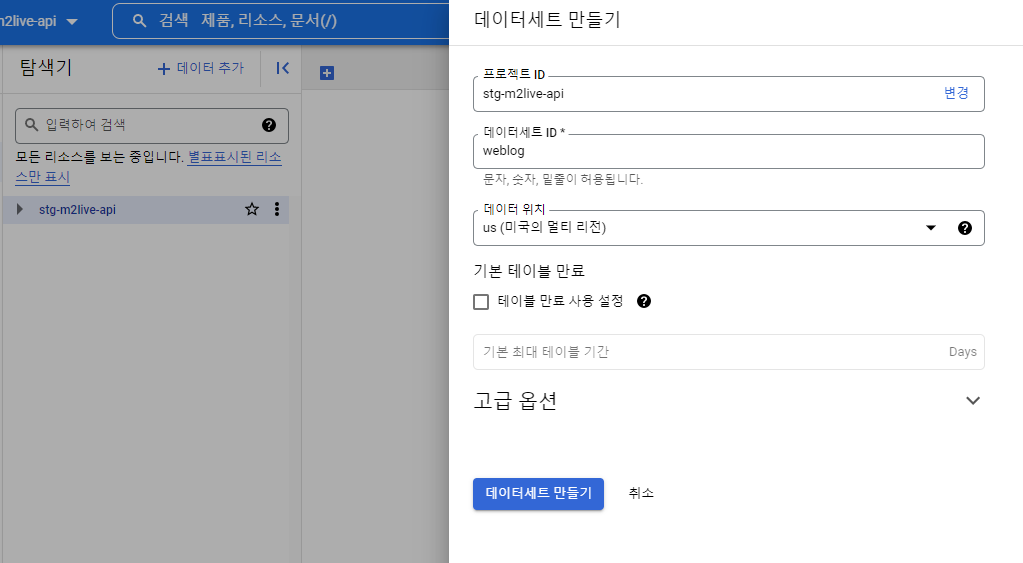
BigQuery 웹콘솔 에 접속하여 데이터 세트를 만든다.
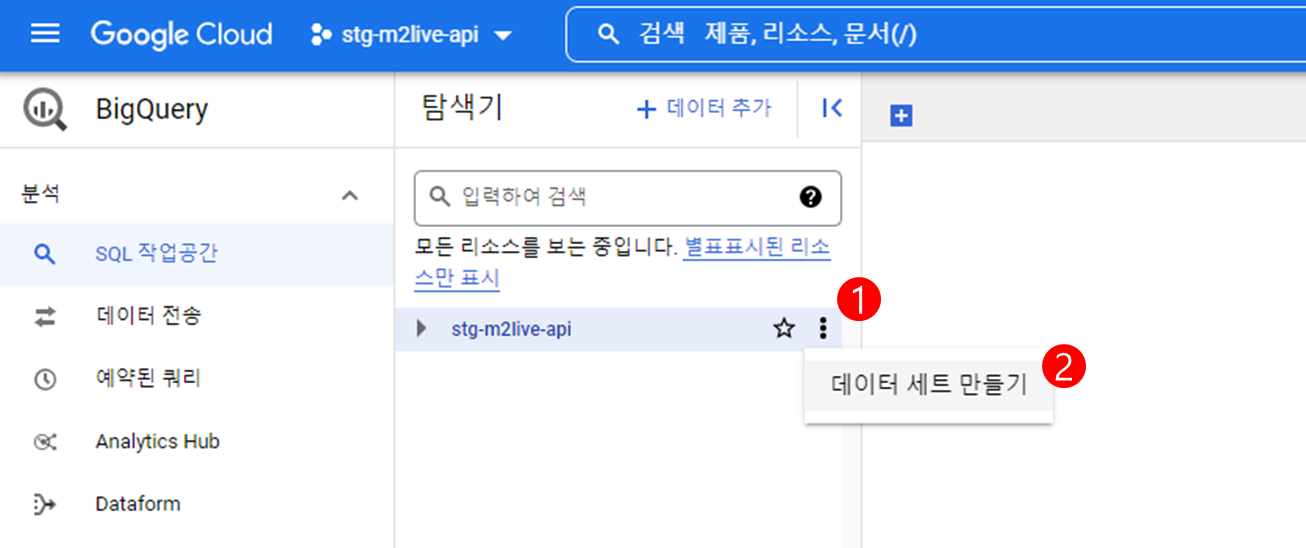
다음 예제에서는 데이터세트 이름을 weblog 로 지정하였다.
BigQuery 테이블 만들기¶
다음은 access.log 에 대한 질의를 위해 weblog.accesslog 테이블을 생성하는 예제이다.
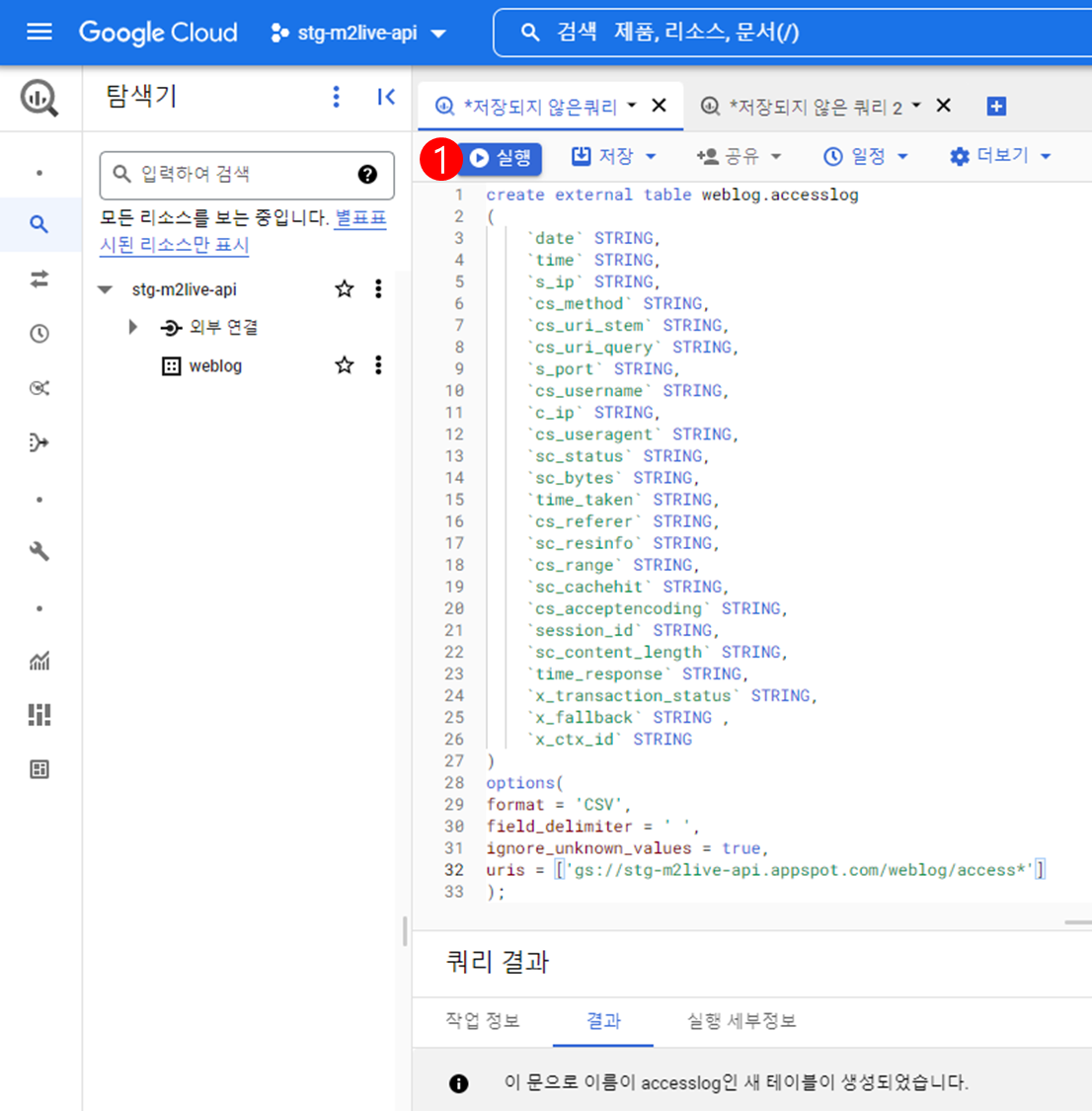
access.log 테이블 생성쿼리는 다음과 같다.
create external table dataset.access_table_name
(
`date` STRING,
`time` STRING,
`s_ip` STRING,
`cs_method` STRING,
`cs_uri_stem` STRING,
`cs_uri_query` STRING,
`s_port` STRING,
`cs_username` STRING,
`c_ip` STRING,
`cs_useragent` STRING,
`sc_status` STRING,
`sc_bytes` STRING,
`time_taken` STRING,
`cs_referer` STRING,
`sc_resinfo` STRING,
`cs_range` STRING,
`sc_cachehit` STRING,
`cs_acceptencoding` STRING,
`session_id` STRING,
`sc_content_length` STRING,
`time_response` STRING,
`x_transaction_status` STRING,
`x_fallback` STRING ,
`x_ctx_id` STRING
)
options
(
format = 'CSV',
field_delimiter = ' ',
ignore_unknown_values = true,
uris = ['gs://your-bucket-name/your-path/access*']
);
Note
첫 번째 라인의
dataset.access_table_name에는 생성한 데이터 세트와 테이블명을 입력한다.마지막 라인의
'gs://your-bucket-name/your-path/access*'에는 Google Storage 내 데이터 경로를 입력한다.
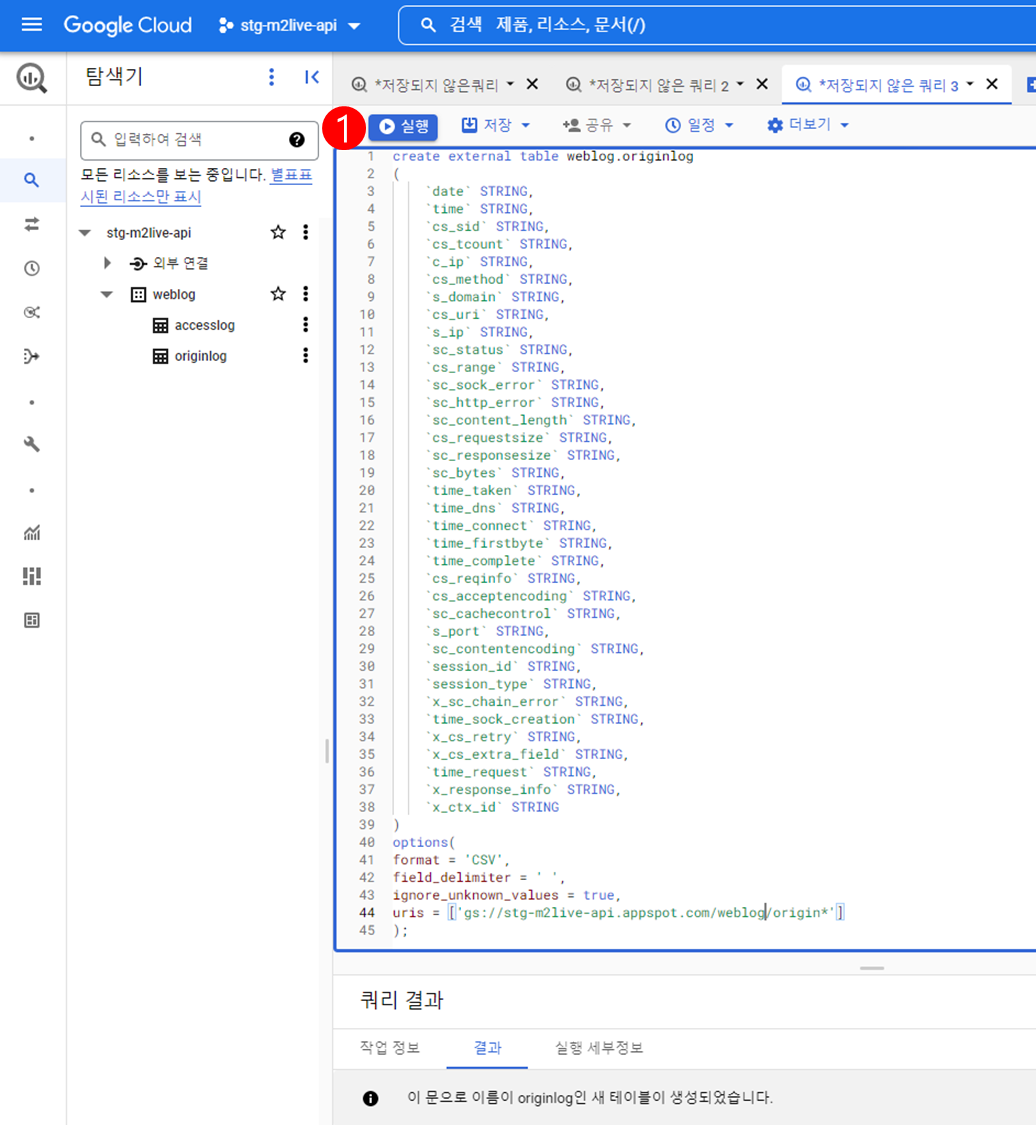
origin.log 테이블 생성쿼리는 다음과 같다.
create external table dataset.origin_table_name
(
`date` STRING,
`time` STRING,
`cs-sid` STRING,
`cs-tcount` STRING,
`c-ip` STRING,
`cs-method` STRING,
`s-domain` STRING,
`cs-uri` STRING,
`s-ip` STRING,
`sc-status` STRING,
`cs-range` STRING,
`sc-sock-error` STRING,
`sc-http-error` STRING,
`sc-content-length` STRING,
`cs-requestsize` STRING,
`sc-responsesize` STRING,
`sc-bytes` STRING,
`time-taken` STRING,
`time-dns` STRING,
`time-connect` STRING,
`time-firstbyte` STRING,
`time-complete` STRING,
`cs-reqinfo` STRING,
`cs-acceptencoding` STRING,
`sc-cachecontrol` STRING,
`s-port` STRING,
`sc-contentencoding` STRING,
`session-id` STRING,
`session-type` STRING,
`x-sc-chain-error` STRING,
`time-sock-creation` STRING,
`x-cs-retry` STRING,
`x-cs-extra-field` STRING,
`time-request` STRING,
`x-response-info` STRING,
`x-ctx-id` STRING
)
options
(
format = 'CSV',
field_delimiter = ' ',
ignore_unknown_values = true,
uris = ['gs://your-bucket-name/your-path/origin*']
);
Note
첫 번째 라인의
dataset.access_table_name에는 생성한 데이터 세트와 테이블명을 입력한다.마지막 라인의
'gs://your-bucket-name/your-path/origin*'에는 Google Storage 내 데이터 경로를 입력한다.
테이블 생성과 관련된 보다 자세한 내용은 BigQuery - 표준 SQL의 데이터 정의 언어(DDL) 문 를 참고한다.
질의와 갱신¶
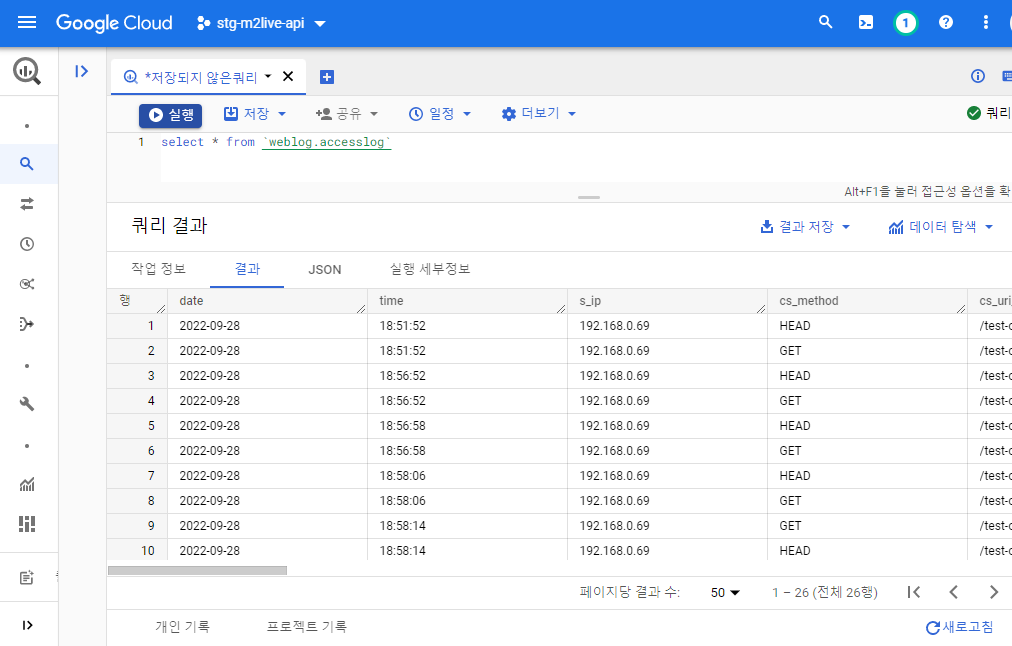
로그 전체에 대한 질의결과는 다음과 같다.
SELECT * FROM `weblog.accesslog`
조건 질의결과는 다음과 같다.
SELECT date,time,cs_uri,sc_status,x_sc_chain_error FROM `weblog.originlog` WHERE x_sc_chain_error != '-'
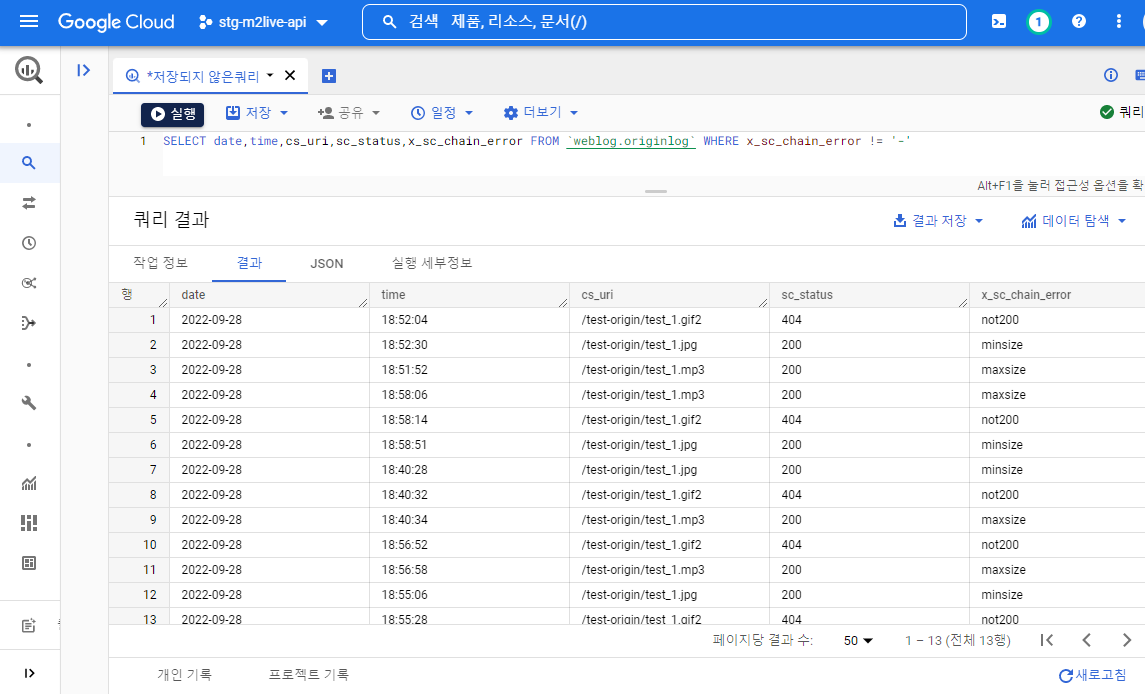
데이터 갱신은 테이블 생성시 데이터 소스로 다음 구문을 통해 * 지정을 했기에 별도의 갱신이 필요치 않다.
uris = ['gs://your-bucket-name/your-path/origin*']