페이지 추출하기¶
아래 원본 URL을 기준으로 ePub 페이지 서비스 구성하는 법을 설명한다.
https://example.com/book.epub
Note
ePub 버전 2부터 3.2까지 지원한다.
기본설정과 단위테스트¶
페이지 추출을 위해 epubedit , unzip 함수를 활성화한다.
{
"hosting": [
{
"name": "example.com",
... (생략) ...
"functions": {
"contents": {
"epubedit": {
"meta" : {
"enable": true,
"keyword": "epubedit"
}
},
"unzip": {
"meta" : {
"enable": true,
"keyword": "unzip"
}
}
}
}
}
]
}
ePub 문서는 압축파일이기 때문에 epubedit 함수는 unzip 함수에 의존성을 가진다.
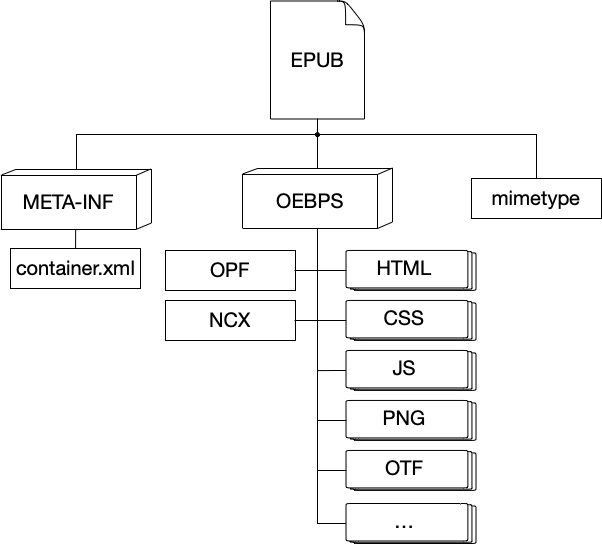
ePub 브라우징¶
ePub 문서의 내부구조는 unzip 함수를 이용해 브라우징이 가능하다.
https://example.com/book.epub/unzip/directory
응답은 json 형식으로 제공되며 주요 필드는 path , uncompressedSize 이다.
[
{
"name": "standard.opf",
"type": "file",
"path": "item/standard.opf",
"uncompressedSize": 50847,
"compressedSize": 4470,
"lastModified": "2021-12-02T16:14:32.000Z",
"extra": {}
},
{
"name": "image",
"type": "directory",
"path": "item/image/",
"uncompressedSize": 0,
"compressedSize": 0,
"lastModified": "2021-12-02T16:14:30.000Z",
"extra": {}
},
{
"name": "cover.jpg",
"type": "file",
"path": "item/image/cover.jpg",
"uncompressedSize": 583696,
"compressedSize": 567974,
"lastModified": "2021-12-02T16:13:00.000Z",
"extra": {}
},
...
]
ePub 개별 리소스 추출¶
ePub 브라우징 의 결과 path 를 사용해 개별 리소스를 추출할 수 있다.
https://example.com/book.epub/unzip/files/{상대경로}
다음과 같이 /unzip/files 명령어 뒤에 path 를 붙여주면 리소스를 서비스할 수 있다.
https://example.com/book.epub/unzip/files/item/image/cover.jpg
페이지 추출하기¶
페이지 추출 정책은 ePub문서 내의 standard.opf 를 기반으로 동작한다.
<manifest>의<item id="...">를 파라미터로 입력받는다.<spine>은 추출된 페이지를 참조(=idref)하는 엘레멘트만 자동으로 추출한다.<manifest>와<spine>이외의 필드는 수정하지 않는다.
<?xml version="1.0" encoding="UTF-8"?>
<package xmlns="http://www.idpf.org/2007/opf" version="3.0">
<manifest>
<item media-type="application/xhtml+xml" id="cover" href="xhtml/cover.xhtml" />
<item media-type="application/xhtml+xml" id="001" href="xhtml/001.xhtml" />
<item media-type="application/xhtml+xml" id="002" href="xhtml/002.xhtml" />
<item media-type="application/xhtml+xml" id="003" href="xhtml/003.xhtml" />
... (생략) ...
<item media-type="application/xhtml+xml" id="149" href="xhtml/149.xhtml" />
<item media-type="application/xhtml+xml" id="150" href="xhtml/150.xhtml" />
</manifest>
<spine page-progression-direction="rtl">
<itemref linear="yes" idref="cover" properties="rendition:page-spread-center"/>
<itemref linear="yes" idref="001" properties="page-spread-left"/>
<itemref linear="yes" idref="002" properties="page-spread-right"/>
<itemref linear="yes" idref="p-003" properties="page-spread-left"/>
... (생략) ...
<itemref linear="yes" idref="149" properties="page-spread-left"/>
<itemref linear="yes" idref="150" properties="page-spread-right"/>
</spine>
</package>
trim 명령어를 통해 원하는 id 를 명시하여 추출한다.
https://example.com/book.epub/src.epub/epubedit/trim/cover,001,002,003,004,005,006,007,008,009,010
id 가 숫자이고 순차적으로 넘버링되었다면 아래와 같은 범위 표현이 가능하다.
https://example.com/book.epub/src.epub/epubedit/trim/cover,001-010
# 100페이지부터 끝까지
https://example.com/book.epub/src.epub/epubedit/trim/100-
# 처음부터 10페이지까지
https://example.com/book.epub/src.epub/epubedit/trim/-100
Important
추출된 페이지는 원본에 명시된 순서대로 정렬된다.
prefix 연결된 리소스 추출하기¶
만화책처럼 페이지와 이미지가 연결된 경우 아래와 같이 다른 prefix 로 페이지 규칙이 부여될 수 있다.
See also
<?xml version="1.0" encoding="UTF-8"?>
<package xmlns="http://www.idpf.org/2007/opf" version="3.0">
<manifest>
<!-- image -->
<item media-type="image/jpeg" id="i-cover" href="image/cover.jpg" properties="cover-image"/>
<item media-type="image/jpeg" id="i-001" href="image/i-001.jpg"/>
<item media-type="image/jpeg" id="i-002" href="image/i-002.jpg"/>
<item media-type="image/jpeg" id="i-003" href="image/i-003.jpg"/>
... (생략) ...
<item media-type="image/jpeg" id="i-149" href="image/i-149.jpg"/>
<item media-type="image/jpeg" id="i-150" href="image/i-150.jpg"/>
<!-- xhtml -->
<item media-type="application/xhtml+xml" id="p-cover" href="xhtml/cover.xhtml"/>
<item media-type="application/xhtml+xml" id="p-001" href="xhtml/001.xhtml"/>
<item media-type="application/xhtml+xml" id="p-002" href="xhtml/002.xhtml"/>
<item media-type="application/xhtml+xml" id="p-003" href="xhtml/003.xhtml"/>
... (생략) ...
<item media-type="application/xhtml+xml" id="p-149" href="xhtml/149.xhtml"/>
<item media-type="application/xhtml+xml" id="p-150" href="xhtml/150.xhtml"/>
</manifest>
위 문서에는 페이지 p-001 과 이미지 i-001 이 연결된 규칙이 존재한다.
따라서 일일이 모든 id 를 명시하지 않고 다음과 같이 간결하게 추출할 수 있다면 효과적일 것이다.
# 변하는 값만 입력하여 모든 리소스를 추출하고 싶다.
https://example.com/book.epub/src.epub/epubedit/trim/cover,001-010
입력된 파라미터를 포함하여, 약속된 문자열로 시작되는 모든 리소스를 추출하려면 다음과 같이 prefix 리스트를 구성한다.
# functions.contents.epubedit.trim
"prefix": [
"i-",
"p-"
]
사용자가 001 값을 입력한다면 다음과 같이 동작한다.
id가001인 리소스를 추출한다.id가i-001인 리소스를 추출한다.id가p-001인 리소스를 추출한다.
Note
범위표현(i.e. 010-020 )은 숫자에 대해서만 가능하다.
따라서 p-010 처럼 문자로 인식되는 id 표현의 경우 prefix 를 활용하여 범위표현이 가능하다.
고정추출 지정하기¶
커버이미지나 css 처럼 1 페이지만 추출하더라도 항상 포함되어야 하는 리소스가 존재한다.
이런 경우 고정추출되도록 구성하면 문서의 일관성을 유지할 수 있다.
See also
<?xml version="1.0" encoding="UTF-8"?>
<package xmlns="http://www.idpf.org/2007/opf" version="3.0">
<manifest>
<item media-type="application/xhtml+xml" id="toc" href="navigation-documents.xhtml" properties="nav"/>
<item media-type="text/css" id="fixed-layout-kr" href="style/fixed-layout-kr.css"/>
<!-- image -->
<item media-type="image/jpeg" id="i-cover" href="image/cover.jpg" properties="cover-image"/>
... (생략) ...
<!-- xhtml -->
<item media-type="application/xhtml+xml" id="p-cover" href="xhtml/cover.xhtml" />
... (생략) ...
아래와 같이 toc 와 fixed-layout-kr 를 직접 입력하게 할 수 있지만 매우 번거롭다.
https://example.com/book.epub/src.epub/epubedit/trim/toc,fixed-layout-kr,cover,001-010
include 설정으로 고정추출 규칙을 지정해 두면 trim 커맨드의 파라미터로 입력하지 않아도 항상 추출됨을 보장할 수 있다.
# functions.contents.epubedit.trim
"include": [
"id=\"toc\""
"<item media-type=\"text/css\" (.*)"
]
이제 다음과 같이 입력하여도 toc 와 fixed-layout-kr 가 항상 추출된다.
https://example.com/book.epub/src.epub/epubedit/trim/cover,001-010
페이지방향 재정렬¶
ePub은 <spine> 을 통해 페이지 방향을 지정한다.
See also
<?xml version="1.0" encoding="UTF-8"?>
<package xmlns="http://www.idpf.org/2007/opf" version="3.0">
<manifest>
... (생략) ...
</manifest>
<spine page-progression-direction="rtl">
<itemref linear="yes" idref="p-cover" properties="rendition:page-spread-center"/>
<itemref linear="yes" idref="p-001" properties="page-spread-left"/>
<itemref linear="yes" idref="p-002" properties="page-spread-right"/>
<itemref linear="yes" idref="p-003" properties="page-spread-left"/>
<itemref linear="yes" idref="p-004" properties="page-spread-right"/>
... (생략) ...
예를 들어 /trim/p-001,p-003 명령어로 추출하면 페이지방향이 left, left 가 되어 방향정렬이 헝클어진다.
이런 경우 페이지 추출 후 페이지방향을 재정렬하도록 설정할 수 있다.
"# functions.contents.epubedit.trim": {
"enable": true,
"order": "auto"
}
위와 같이 설정하면 원본페이지의 첫 페이지방향을 기준으로 추출된 페이지를 재정렬한다.
예제의 /trim/p-001,p-003 의 결과는 left, right 로 재정렬된다.