최적화¶
최적화와 그 밖의 잡다하지만 깊이 있는 주제에 대해 다룬다. 최적화는 고성능(High Performance)을 위한 방법이며 이는 우리가 추구하는 가장 큰 가치다. 엔터프라이즈 환경에서의 고성능은 주어진 하드웨어 자원을 최대한 활용하는 것을 의미하기도 한다.
메모리 인덱싱¶
메모리는 모든 설계 및 정책을 결정하는 가장 중요한 자원이다. 특히 인덱싱(요청된 URL을 빠르게 찾는 것)에 대해서는 반드시 이해해야 한다.
Physical RAM |
System Free |
Contents |
Caching Count |
Sockets |
|---|---|---|---|---|
1GB |
409.60MB |
188.37MB |
219,469 |
5,000 |
2GB |
819.20MB |
446.74MB |
520,494 |
10,000 |
4GB |
1.60GB |
963.49MB |
1,122,544 |
20,000 |
8GB |
3.20GB |
2.05GB |
2,440,422 |
20,000 |
16GB |
6.40GB |
4.45GB |
5,303,733 |
20,000 |
32GB |
12.80GB |
9.25GB |
11,030,356 |
20,000 |
64GB |
25.60GB |
18.85GB |
22,483,603 |
20,000 |
128GB |
51.20GB |
38.05GB |
45,390,095 |
20,000 |
서비스 품질을 결정하는 요소는 인덱싱과 탐색이다. 앞으로 설명할 모든 내용은 위 표 물리 메모리 크기에 따른 기본설정 와 관련이 있다.
히트율¶
먼저 클라이언트의 HTTP요청이 어떻게 처리되는지 이해해야 한다.
캐시처리 결과는 Squid와 동일하게 TCP_* 로 명명되며 각 표현마다 캐시서버가 처리한 방식을 의미한다.
TCP_HIT요청된 리소스(만료되지 않음)가 캐싱되어 있어 즉시 응답함.TCP_IMS_HITIMS(If-Modified-Since)헤더와 함께 요청된 리소스가 만료되지 않은 상태로 캐싱되어 있어304 Not Modified로 응답함Note
policies 의
extendBy4xx,extendBy5xx설정에 해당하는 경우에도 이에 해당함.TCP_REFRESH_HIT요청된 리소스가 만료되어 원본서버 확인(원본 미변경,304 Not Modified) 후 응답함. 리소스 만료시간 연장됨.TCP_REF_FAIL_HITTCP_REFRESH_HIT과정 중 원본서버에서 확인이 실패(접속실패, 전송지연)한 경우 만료된 컨텐츠로 응답함.TCP_NEGATIVE_HIT요청된 리소스가 비정상적인 상태(원본서버 접속/전송 실패, 4xx응답, 5xx응답)로 캐싱되어 있고 해당상태를 응답함.TCP_REDIRECT_HIT서비스 허용/거부/Redirect 조건에 의해 Redirect를 응답함.TCP_MISS요청된 리소스가 캐싱되어 있지 않음(=최초 요청). 원본서버에서 가져온 결과를 응답함.TCP_REFRESH_MISS요청된 리소스가 만료되어 원본서버 확인(원본 변경,200 OK) 후 응답함. 새로운 리소스가 캐싱됨.TCP_CLIENT_REFRESH_MISS요청을 원본서버로 바이패스.TCP_CLIENT_INSTANT_MISS요청을 원본서버로instant모드로 바이패스.TCP_ERROR요청된 리소스가 캐싱되어 있지 않음(=최초 요청). 원본서버 장애(접속실패, 전송지연, 원본배제)로 인해 리소스를 캐싱하지 못함. 클라이언트에게500 Internal Error로 응답함.TCP_DENIED요청이 거부되었음.
이상을 종합하여 히트율 계산식은 다음과 같다.
TCP_HIT + TCP_IMS_HIT + TCP_REFRESH_HIT + TCP_REF_FAIL_HIT + TCP_NEGATIVE_HIT + TCP_REDIRECT_HIT
------------------------------------------------------------------------------------------------
SUM(TCP_*)
Byte 히트율¶
클라이언트에게 전송한 트래픽(Client Outbound)대비 원본서버로부터 전송받은 트래픽(Origin Inbound)의 비율을 나타낸다. 원본서버 트래픽이 클라이언트 트래픽보다 높은 경우 음수가 나올 수 있다.
Client Outbound - Origin Inbound
--------------------------------
Client Outbound
Memory-Only 모드¶
Memory-Only 모드란 디스크를 이용하지 않고 컨텐츠를 메모리에만 적재하는 방식을 말한다. localCacheStorage 을 하지 않으면 자동으로 Memory-Only모드로 동작한다.
{
"env": {
"rt": {
"localCacheStorage": {
"disk": null
}
}
}
이 모드는 ttl 이 짧거나 컨텐츠 크기가 작은 경우 유용하다.
HLS 라이브 방송
가격/재고
티켓 조회
실시간 순위
검색
API
반대로 컨텐츠 크기가 GB단위로 크거나 ttl 이 긴 서비스에서는 부적합하다.
Note
동적으로 변경이 불가능하다. 설정변경 후 반드시 서비스를 재가동해야 한다.
Volatile 가상호스트¶
특정 가상호스트만 Memory-Only 모드 로 동작하도록 지정한다. 이를 Volatile 가상호스트 라고 부른다.
{
"hosting": [
{
"name": "foo.com",
"mode": {
"volatile": true
}
}
]
}
Memory-Only 모드 라면 volatile 설정은 무시된다.
디스크모드라면 "volatile": true" 인 가상호스트는 Memory-Only 모드 로 동작한다.
Instant 모드¶
가상호스트가 서비스하는 콘텐츠가 1회성이거나 아주 짧은 시간만 유효할 경우 Instant 모드 가 효과적이다.
{
"hosting": [
{
"name": "foo.com",
"mode": {
"instant": true
}
}
]
}
"instant": true 이라면 서비스 중인 콘텐츠 외에는 모두 즉시 삭제된다.
캐싱 객체를 LRU로 관리하지 않으며, 사용이 끝나는 즉시 삭제한다.
디스크로 백업하거나 인덱싱하지 않는다.
메모리 구조¶
캐시서버와 범용 웹서버의 동작방식은 유사하나 목적은 매우 다르다. M2의 구조와 동작방식을 상세히 이해하면 보다 최적화된 서비스가 가능하다.
Note
최적화의 목적은 아래와 같다.
높은 처리량. 성능저하 없이 수 만개의 세션을 동시에 처리할 수 있다.
빠른 반응성. 클라이언트에게 지연없는 서비스를 제공한다.
원본서버 부하절감. 원본서버 부하는 자칫 전체장애로 이어진다.
다음 그림은 M2를 8GB와 16GB메모리 장비에서 구동시켰을 때의 메모리 구성이다.
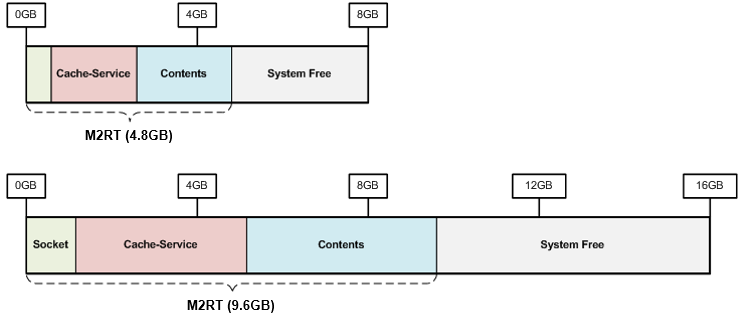
메모리는 M2가 사용하는 메모리와 사용하지 않는 메모리(Free)로 나눈다. M2가 사용하는 메모리는 파일, 소켓같이 서비스 규모에 따라 달라지는 자원 개수와 관련이 있다.
Note
시스템 부하의 근본은 디스크 I/O 때문이다. 당신은 “얼마나 많은 Contents를 Caching해야 디스크 I/O를 줄일 수 있는가?” 에 대해 고민해야 한다.
메모리 조절¶
메모리 구조 는 구동될 때 물리 메모리 크기에 기반하여 계산된다.
See also
properties 의
memoryRatio
memoryRatio 설정은 물리메모리를 기준으로 사용할 메모리 비율을 설정한다.
예를 들어 8GB장비에서 memoryRatio 를 50 으로 설정하면 물리 메모리가 4GB인 것처럼 동작한다.
이는 메모리를 점유하는 다른 프로세스와 같이 구동될 때 유용하게 사용될 수 있다.
좀 더 구체적으로 서비스 형식에 따라 메모리에 적재되는 데이터 비율을 조절하면 효과적이다.
See also
properties 의
memoryRatioContents
memoryRatioContents M2가 사용하는 전체 메모리 중 서비스 데이터 메모리 적재비율을 설정한다.
예를 들어 게임 포탈처럼 파일개수는 적지만 컨텐츠 크기가 클 경우엔 이 수치를 늘리면 파일 I/O가 감소된다. 반대로 아주 작은 파일이 많은 경우는 반대로 줄이는 설정이 유용할 수 있다.
시스템 Free 메모리¶
OS(Operating System)가 느리면 어떠한 프로그램도 제 성능을 내지 못한다. M2는 OS를 위해 일부 메모리를 사용하지 않는다. OS의 성능을 극대화하기 위해서이며 이를 시스템 Free메모리라 부른다.
Note
이에 대해 권위있는 설명을 제시하고 싶으나 아쉽게도 찾지 못하였다. 구글링을 통해 가장 많이 인용된 글 을 제시한다.
Physical RAM |
System Free |
|---|---|
1GB |
409.6MB |
2GB |
819.2MB |
4GB |
1.6GB |
8GB |
3.2GB |
16GB |
6.4GB |
32GB |
12.8GB |
64GB |
25.6GB |
128GB |
51.2GB |
고급 사용자의 경우 서비스 형태에 맞추어 Free메모리 비율을 줄일 수 있다. Free메모리가 줄어들면 더 많은 Contents를 메모리에 적재할 수 있다.
See also
properties 의
memoryRatioFree
Caching 서비스 메모리¶
클라이언트에게 전송할 컨텐츠를 Caching하는 메모리이다. 한번 디스크에서 메모리로 적재된 컨텐츠는 메모리 부족현상이 발생하지 않는다면 계속 메모리에 존재한다. 문제는 메모리 부족현상은 항상 발생한다는 점이다.

위 그림처럼 전송해야할 컨텐츠는 디스크에 가득한데 실제 메모리에 적재할 수 있는 용량은 아주 제한적이다. 32GB의 물리 메모리를 장착한다해도 고화질 동영상이나 게임 클라이언트의 크기를 감안한다면 그리 넉넉한 편은 아니다. 아무리 효율적으로 메모리를 관리해도 물리적인 디스크 I/O속도에 수렴할 수 밖에 없다.
가장 효과적인 방법은 Contents메모리 공간을 최대한 확보하여 디스크 I/O를 줄이는 것이다. 다음은 물리 메모리 기준으로 M2가 기본으로 설정하는 최대 Contents메모리 크기이다.
Physical RAM |
Contents |
Caching Count |
|---|---|---|
1GB |
188.37MB |
219,469 |
2GB |
446.74MB |
520,494 |
4GB |
963.49MB |
1,122,544 |
8GB |
2.05GB |
2,440,422 |
16GB |
4.45GB |
5,303,733 |
32GB |
9.25GB |
11,030,356 |
64GB |
18.85GB |
22,483,603 |
128GB |
38.05GB |
45,390,095 |
Socket 메모리¶
소켓도 메모리를 사용한다. 4GB이상의 장비에서 M2는 2만개의 소켓을 기본으로 생성한다. 소켓 1개=10KB, 1만개당 97.6MB의 메모리를 사용하므로 약 195MB의 메모리가 기본으로 소켓에 할당된다.
Physical RAM |
Socket Count |
Socket Memory |
|---|---|---|
1GB |
5천 |
50MB |
2GB |
1만 |
97.6MB |
4GB 이상 |
2만 |
195MB |
다음 그림처럼 소켓을 모두 사용하면 자동으로 소켓이 늘어난다.

위 그림과 같이 증설되어 3만개의 소켓을 사용한다면 총 240MB의 메모리가 소켓에 할당된다. 필요한 소켓을 필요한만큼만 사용하는 것은 아무 문제가 없어 보인다. 하지만 사용하지 않는 소켓을 지나치게 많이 설정해놓는 것은 메모리 낭비다. 예를 들어 10Gbps장비에서 사용자마다 10Mbps의 전송속도를 보장한다고 가정했을 때 다음 공식에 의하여 최대 동시 사용자는 1,000명이다.
10,000Mbps / 10Mbps = 1,000 Sessions
이 경우 M2가 최초 생성하는 2만개 중 19,000개에 해당하는 약 148MB는 낭비가 되는 셈이다. 이 148MB를 Contents에 투자한다면 효율을 더 높일 수 있다. 최소 소켓수를 설정하면 메모리를 보다 효율적으로 사용할 수 있다.
최소 소켓수. 최초에 할당되는 소켓수를 의미한다.
증설 소켓수. 소켓이 모두 사용 중(Established)일 때 설정한 개수만큼 소켓을 증설한다.
또 하나의 중요한 변수는 클라이언트 session Keep-Alive시간 설정이다.

연결된 모든 소켓이 데이터 전송 중에 있는 것은 아니다. IE, Chrome과 같은 브라우저들은 다음에 발생할 HTTP전송을 위해 소켓을 서버에 접속해 놓은 상태로 유지한다. 실제로 쇼핑몰의 경우 연결되어 있는 세션 중 아무런 데이터 전송이 발생하지 않고 그저 붙어 있는 세션의 비율은 적게는 50%에서 많게는 80%에 이른다.
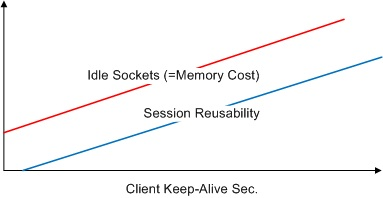
Keep-Alive시간을 길게 줄수록 소켓의 재사용성은 좋아지지만 유지되는 Idle소켓의 개수가 증가하므로 메모리 낭비가 심해진다. 그러므로 서비스에 맞는 적절한 클라이언트 Keep-Alive시간을 설정하는 것이 중요하다.
TCP Segmentation Offload¶
Important
10G NIC를 사용한다면 TSO(TCP Segmentation Offload)를 OFF로 설정하길 권장한다.
TCP는 전송시 패킷을 분할(Segmentation)하는데, 이 작업을 CPU가 아닌 NIC가 수행하도록 설정하는 것이 TSO이다. (기본 값은 ON이다.) 하지만 10G NIC 서비스 환경에서 우리는 이와 관련된 많은 장애를 겪었다.
TCP 패킷 유실 및 지연
TCP 연결 종료
Load Average의 비정상적인 증가
결론적으로 TSO는 모두의 기대만큼 높은 성능을 내지 못하는 것으로 추정된다. (NIC만 1G로 바꿔도 이런 문제는 발생하지 않았다.) 결론적으로 TSO를 OFF로 설정함으로써 서비스는 정상화되었다. 이에 따른 CPU 사용량은 우려할 수준이 아니며 서비스 규모와 비례하는 정직한 지표를 보여 준다.
TSO 설정은 다음과 같이 설정/확인할 수 있다. (K의 대/소문자에 유의한다.)
# ethtool -K ethX tso off // TSO OFF 설정
# ethtool -k ethX // 설정 열람
...
tcp segmentation offload: on
...
원본서버 장애상황 정책¶
고객이 언제든지 원본서버를 점검 할 수 있도록 하는 것이 개발팀의 목표다. 원본서버의 장애가 감지되면 해당 서버는 자동으로 배제되어 복구모드로 전환된다. 장애서버가 재가동되었더라도 정상 서비스 상태를 확인해야만 다시 투입한다.
만약 모든 원본서버의 장애를 감지한 경우 현재 캐싱된 컨텐츠로 서비스를 진행한다. TTL이 만료된 컨텐츠는 원본서버가 복구될 때까지 자동으로 연장된다. 심지어 Purge된 컨텐츠의 경우에도 원본서버에서 캐싱할 수 없다면 복구시켜 서비스에 문제가 없도록 동작한다. 최대한 클라이언트에게 장애상황을 노출해선 안된다는 정책이다. 완전 장애상황에서 신규 컨텐츠 요청이 들어오면 다음과 같은 에러 페이지와 이유가 명시된다.

왠만하면 이런 화면은 보여주기 싫다.¶
디스크 Hot-Swap¶
서비스 중단없이 디스크를 교체한다.
파라미터는 반드시 disks 의 mount 값과 같아야 한다.
http://127.0.0.1:10040/command/unmount?disk=...
http://127.0.0.1:10040/command/umount?disk=...
배제된 디스크는 즉시 사용되지 않으며 해당 디스크에 저장되었던 모든 컨텐츠는 무효화된다. 관리자에 의해 배제된 디스크의 상태는 “Unmounted”로 설정된다.
디스크를 서비스에 재투입하려면 다음과 같이 호출한다.
http://127.0.0.1:10040/command/mount?disk=...
재투입된 디스크의 모든 콘텐츠는 무효화된다.
디스크 정리용량 설정¶
디스크 공간이 부족할 때 캐싱용량의 약 20%(+- 20GB)를 삭제한다. 이는 디스크 크기와 서비스 유형에 따라 너무 많을수도 또는 적을수도 있다. 디스크별로 정리용량을 적절히 설정해 효율을 높일 수 있다.
See also
{
"env": {
"rt": {
"localCacheStorage": {
"cleanup": {
"defaultDiskCleanupSize": 100
},
"disks": [
{
"mount": "/usr/cache1",
"cleanupSize": 50
},
{
"mount": "/usr/cache2"
}
]
}
}
}
}
위 예제는 다음과 같이 동작한다.
/usr/cache1디스크 공간이 한계에 이르면50GB를 정리하여 공간을 확보한다./usr/cache2디스크 공간이 한계에 이르면defaultDiskCleanupSize값인100GB를 정리하여 공간을 확보한다.
캐싱객체 삭제개수 설정¶
캐싱객체가 최대 개수에 다다르면 가장 접근빈도가 낮은 10%의 객체를 삭제한다. 이런 정책은 범용성을 가지지만, 간혹 고용량 메모리 환경에서 불합리할 수도 있다.
예를 들어 3,000만개의 캐싱객체 중 10%만 해도 300만 개라는 매우 큰 숫자가 나온다. 서비스에 따라 TTL이 많이 남은 300만개를 한번에 정리하는 것은 백엔드에 부담을 줄 수 있다.
See also
cleanup 의
fileCount
Note
최소 10만개 이상을 권장한다.
SyncStale¶
(인덱싱시점과 성능상의 이유로) 비정상 서비스 종료시 Purge 한 컨텐츠가 인덱싱에서 누락될 수 있다. 이를 보완하기 위해 API호출을 로그로 기록하여 서비스 재가동시 반영한다.
See also
cleanup 의
enableSyncStale
로그는 ./stale.log에 기록되며 정상종료 또는 정기 인덱싱 시점에 초기화된다.
RRD 비활성화¶
M2는 시계열 데이터를 그래프로 제공하기 위해 RRD를 사용한다. ( /graph API 참조 ) 다음의 경우 이 기능을 비활성화하는 것이 더 나은 선택일 수 있다.
ELK 등 별도의 통계 시스템을 운영하고 있는 경우
마이크로 서버와 같이 열약한 서버 환경에도 구동되어야 하는 경우
가상호스트가 지나치게 많아 RRD 연산의 부하가 높은 경우
See also
properties 의
enableRrd